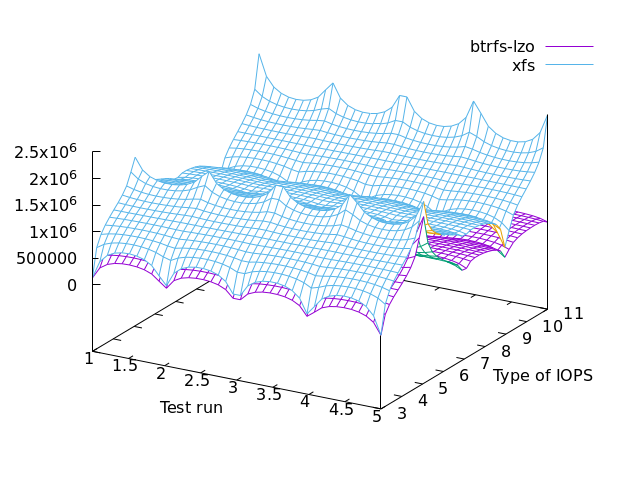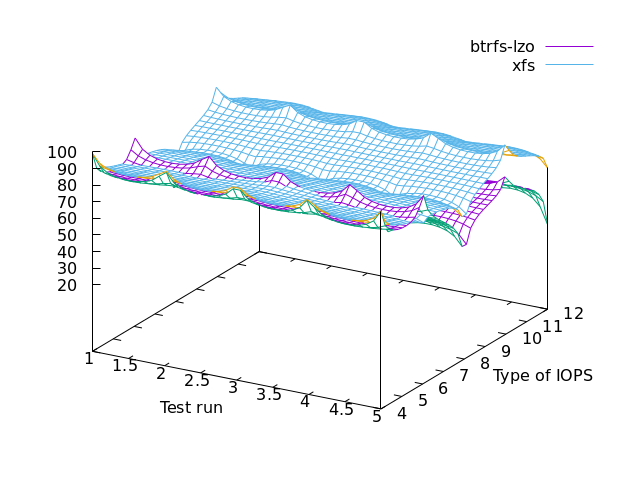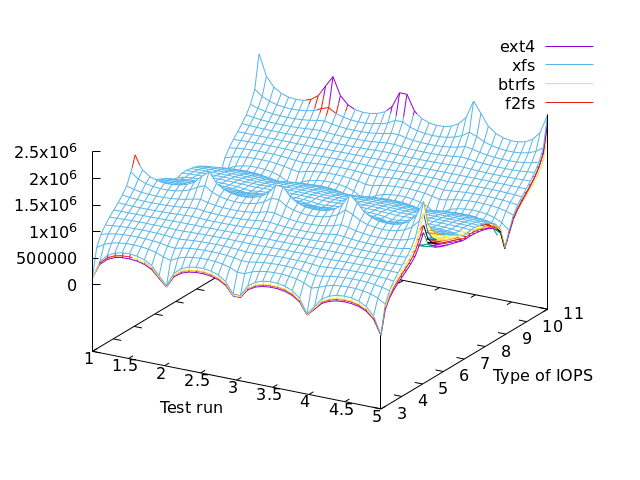
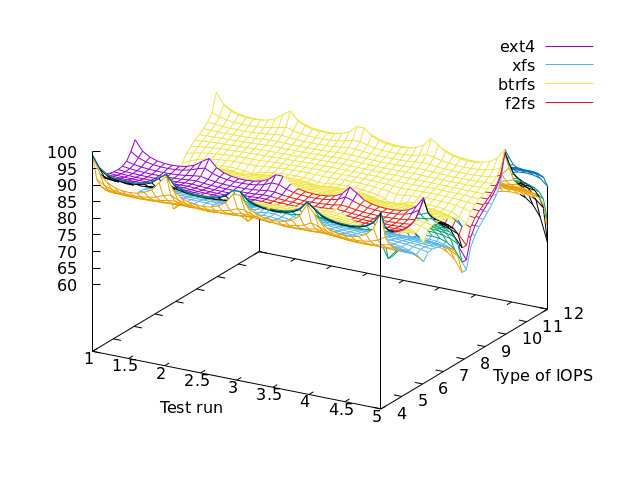
This is Bonnie++ v1.04 against a PNY CS3040 500GB SSD (NVMe) powered by AMD Ryzen 9 5950X with the v5.16 Linux kernel + reiser4 patch, but with only 2GiB of RAM (as it’s a XEN dom0 host). Every test has been repeated 5 times (runs).
Type of IOPS refers to the Bonnie++ results column.
col 3,4 -- disk output char
col 5,6 -- disk output block
col 7,8 -- disk output rewrite
col 9,10 -- disk input char
col 11,12 -- disk input block
First things first, let’s start with file-systems without compression.
overall performance (more is better) & cpu usage (less is better)
==> not much difference but if you want a winner, that’s XFS
Now what’s the most efficient algorithm whatever the file-system we are considering?
butterfs specific (performance & cpu usage)
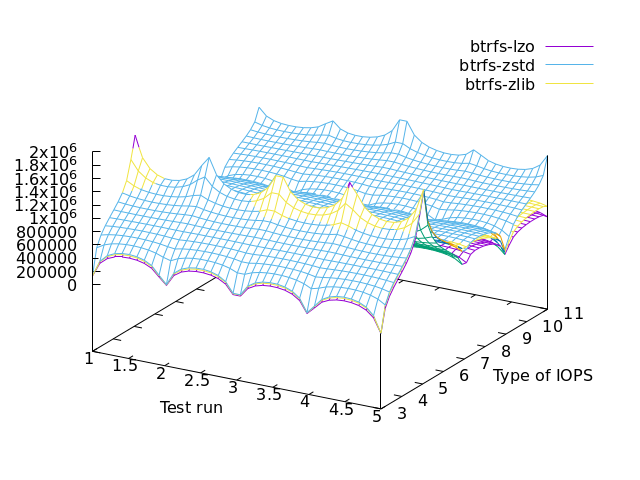
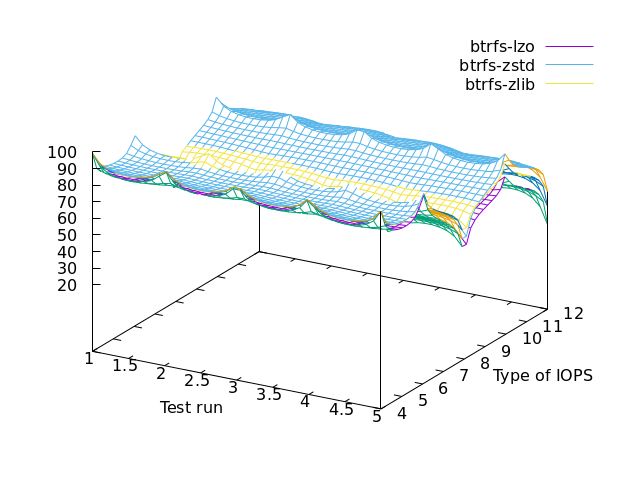
==> ZSTD (that’s level 3 by default) for performance
==> LZO for lazy cpu
reiser4 specific (performance & cpu usage)
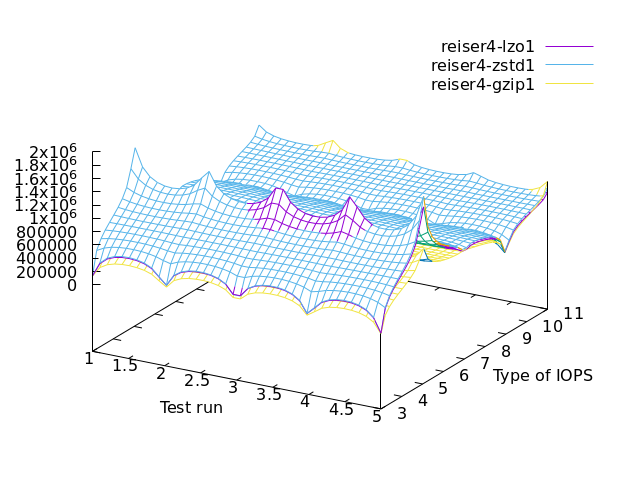
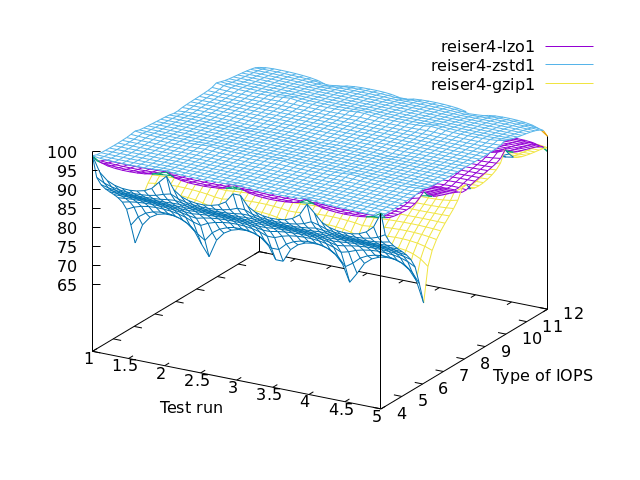
==> ZSTD for performance
==> GZIP for lazy cpu
lzo specific
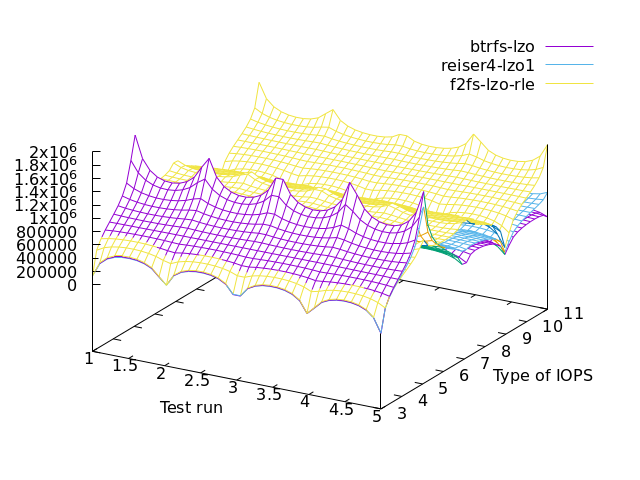
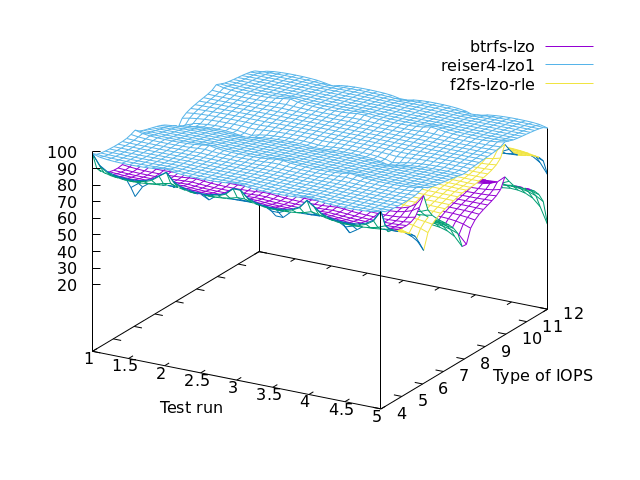
==> F2FS for performance
==> BUTTERFS for lazy cpu
zstd specific
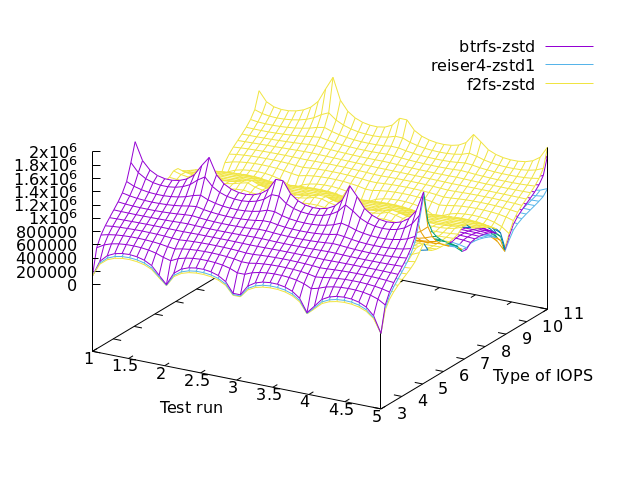
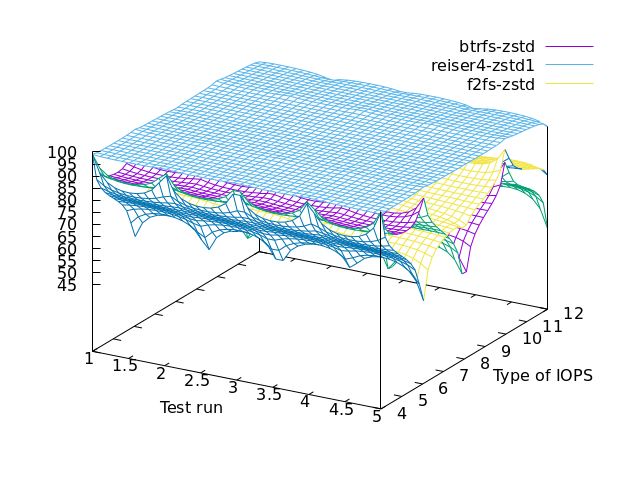
lz4 specific – only f2fs has lz4 hence we’re comparing against itself
We’re using a dedicated volume on an idling server that could be dedicated for benchmarking.
lvcreate --virtualsize=5G --thin -n bonnie thin/pool
The following options were used.
# RAM 1G
bonnie++ -u root -x 5 -r 1024 -m FS-KEYWORD-HERE -d /var/tmp/bonnie/
More details on file-system mount options: https://lab.nethence.com/fsbench/2022-10/ –> look for -features.txt and -mount-options.txt
The script for running the benchmark bulk: https://pub.nethence.com/bin/benchmarks/bonnie-auto.ksh.txt and its archived version.
The script for generating the graphs: https://pub.nethence.com/bin/benchmarks/bonnie-gnuplot-auto.ksh.txt and its archived version.
Tools' versions
e2fsprogs-1.46.5-x86_64-1
xfsprogs-5.13.0-x86_64-1
btrfs-progs-5.16-x86_64-1
reiser4progs-1.2.2-x86_64-1_SBo
f2fs-tools-1.14.0-x86_64-3
F2FS (log-structured for SSDs) seems to rock everything out including butterfs and reiser4.
It is interesting to note that when compression is enabled, read operations become slower than write operations although cpu usage is not high (resp. cols 9 11 vs. 2 5 7 on the left-hand graph). As a matter of fact, when reading, butterfs esp. LZO consumes even less cpu compared to casual file-systems (cols 8 10 12 on the right-hand graph).